We are excited to announce the release of Apache Doris 1.2.0 on December 7, 2022! We take this opportunity to extend our heartfelt appreciation to the 118 contributors who have made over 2400 commits to the open source Apache Doris project.
Under the LTS version management mechanism, the previous Apache Doris 1.1.X versions have focused on bug fixing and stability guarantee. Now, it is time to provide users with a new taste. Apache Doris 1.2.0 is a comprehensively upgraded version with a surprising number of new features that can meet the needs of general users and developers.
In Apache Doris 1.2.0, we provide:
- Full Vectorized-Engine support that brings greatly improved performance
- Merge-on-Write support on Unique Key Model, which reduces query overhead and largely improves the reading efficiency on the updateable data model
- Multi Catalog that enables Doris to quickly access external data sources including Hive Metastore, Elasticsearch, and JDBC
- Light Schema Change, alllowing millisecond-level Schema Change operations and DML and DDL synchronization from upstream databases to Doris via Flink CDC
- JDBC Facade in replacement of ODBC Facade
- Support for Java UDF, Remote UDF, Array data type, and JSONB data type
Download & Install
Download from GitHub: https://github.com/apache/doris/releases
Download from official website: https://doris.apache.org/download
Source code: https://github.com/apache/doris/releases/tag/1.2.0-rc04
Downloading Instructions
Due to the file size limit of the Apache server, the Doris 1.2.0 binary program is divided into 3 packets, which you may download from the Doris website:
apache-doris-fe
apache-doris-be
apache-doris-java-udf-jar-with-dependencies
apache-doris-java-udf-jar-with-dependenciesis added to support the new JDBC external tables and Java UDF in Doris 1.2.0. After downloading, please find thejava-udf-jar-with-dependencies.jarfile in this packet and put it under thebe/libdirectory. This is necessary for the startup of BE.
For your convenience, we offer the precompiled binary program packets of Apache Doris 1.2.0 with a built-in Java 8 runtime environment. Click the links below and start downloading immediately:
- ARM64:https://selectdb-doris-1308700295.cos.ap-beijing.myqcloud.com/release/selectdb-doris-1.2.0-arm.tar.gz
- x86:https://selectdb-doris-1308700295.cos.ap-beijing.myqcloud.com/release/selectdb-doris-1.2.0-x86_64.tar.gz
- x86_no_avx2:https://selectdb-doris-1308700295.cos.ap-beijing.myqcloud.com/release/selectdb-doris-1.2.0-x86_64-no-avx2.tar.gz
Deployment Instructions
To upgrade to Apache Doris 1.2.0, you need to update the bin and lib directories under fe and be.
For more details, you may refer to:
- The Notes for Version Upgrade section on this page
- Install & Deploy Documentation: https://doris.apache.org/docs/dev/install/install-deploy/
- Cluster Upgrade Documentation: https://doris.apache.org/docs/dev/admin-manual/cluster-management/upgrade/
You can always contact SelectDB engineers for help with version upgrading, feature verification, and production.
Highlights
Full Vectorized-Engine Support
All system modules are vectorized in Apache Doris 1.2.0, including Data Loading and Unloading, Schema Change, Compaction, and UDFs. The new vectorized engine can perfectly work in replacement of the old non-vectorized engine, so we are considering removing the code of the latter in future versions.
Besides vectorization, we have conducted full-link optimization covering data scanning, predicate computing, Aggregation ops, HashJoin ops, and Shuffle between ops. All this results in much faster performance.
Tests on various standard test sets show that Apache Doris 1.2.0 runs nearly 4 times as fast as 1.1.3 and 10 times as 0.15.0 in SSB-100-Flat scenarios. While in complex TPCH-100 scenarios, it reports 3-time and 11-time performance enhancements against 1.1.3 and 0.15.0, respectively.
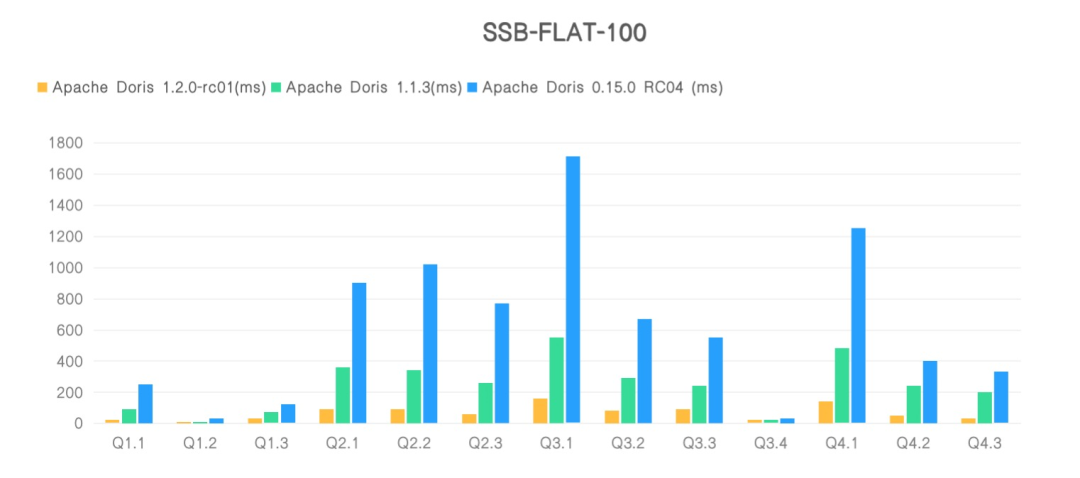
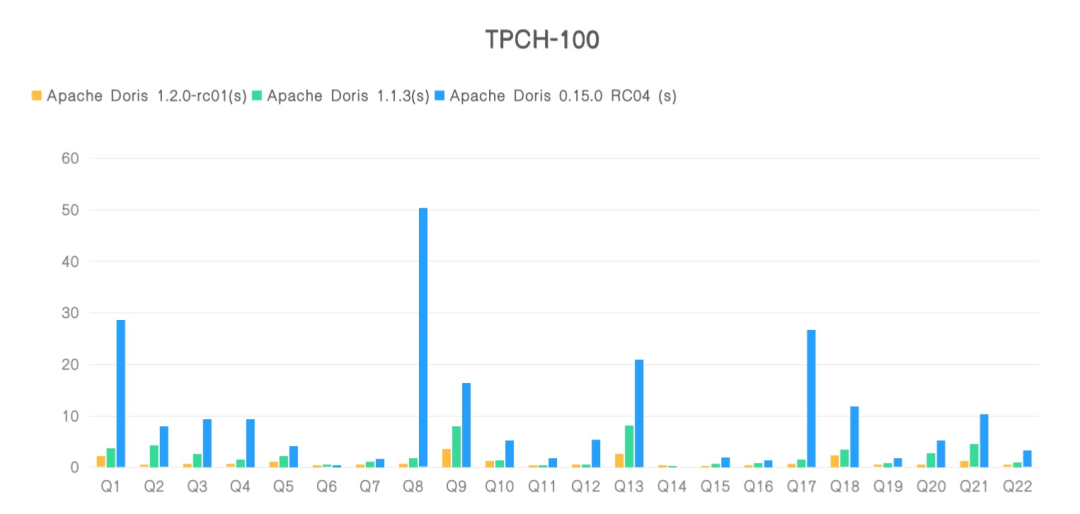
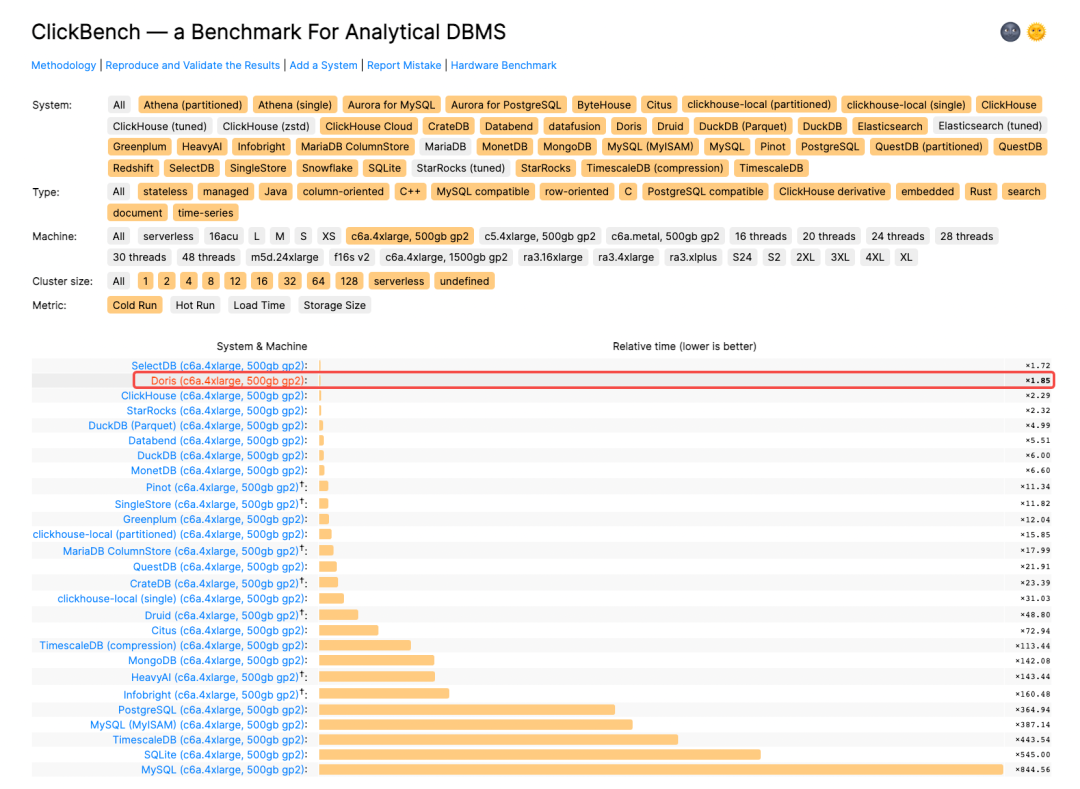
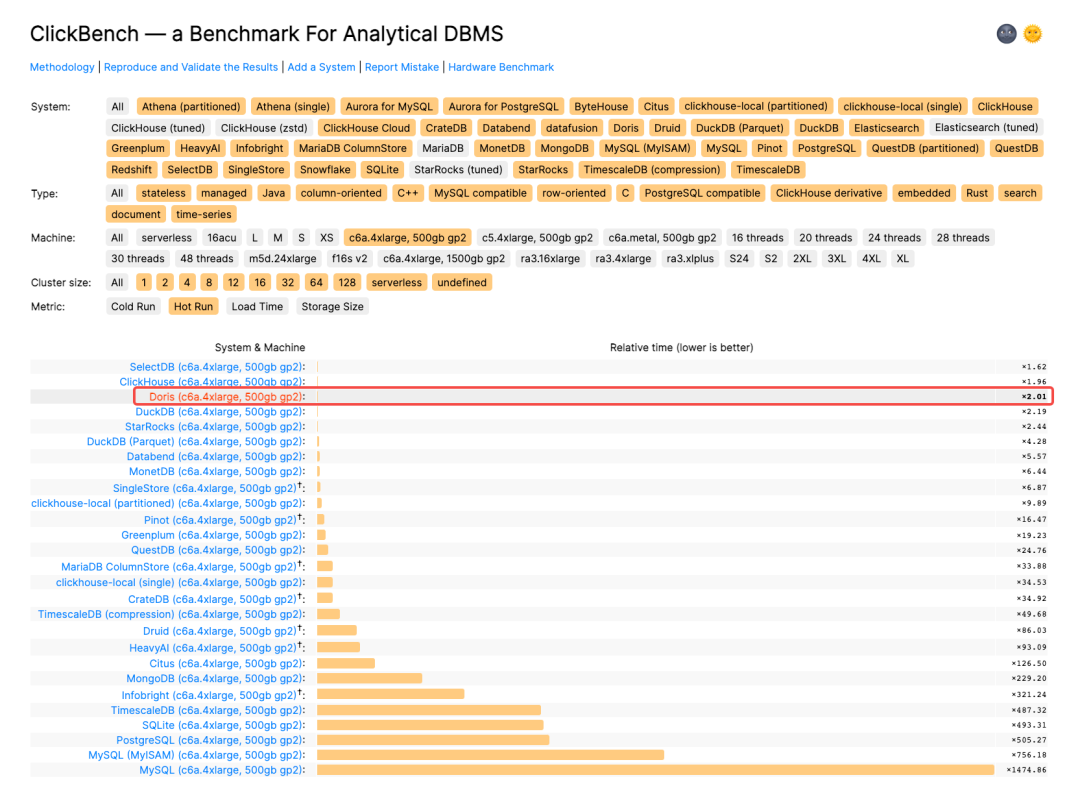
After submitting the test results to ClickBench, an internationally recognized benchmark for databases, we proudly found out that Apache Doris 1.2.0 won second place in Cold Run and third place in Hot Run for the universal machine (c6a.4xlarge, 500gb gp2) in terms of query performance, with 8 SQLs being record-breakers. It tops the list of writing performance under the same machine model as it is able to write 70G of data within merely 415s and achieves a single-node write speed of over 170 MB/s.
Merge-on-Write on Unique Key Model
In older versions, Apache Doris realizes real-time update of data with the Unique Key data model. However, the Merge-on-Read implementation of this method can incur problems, including efficiency bottlenecks, unnecessary computing resource consumption and IO overheads, and jitters in queries.
That's why we added the Merge-on-Write data update mode. It marks the data that needs to be deleted or updated when the data is written, as a way to ensure the uniqueness of primary key in data writing. This has saved the trouble of deduplicating the primary keys in data reading, and thus reducing extra resource consumption in queries. In addition, this method supports predicate pushdown. It can make good use of the various indexing in Doris to performs data cropping on the IO level, reducing the data processing volume in reading and computing. This is how it brings significant performance increases in multiple query scenarios.
Simulation tests of various continuous data loading scenarios on the SSB-Flat dataset report 3~6 times performance improvements in most queries.
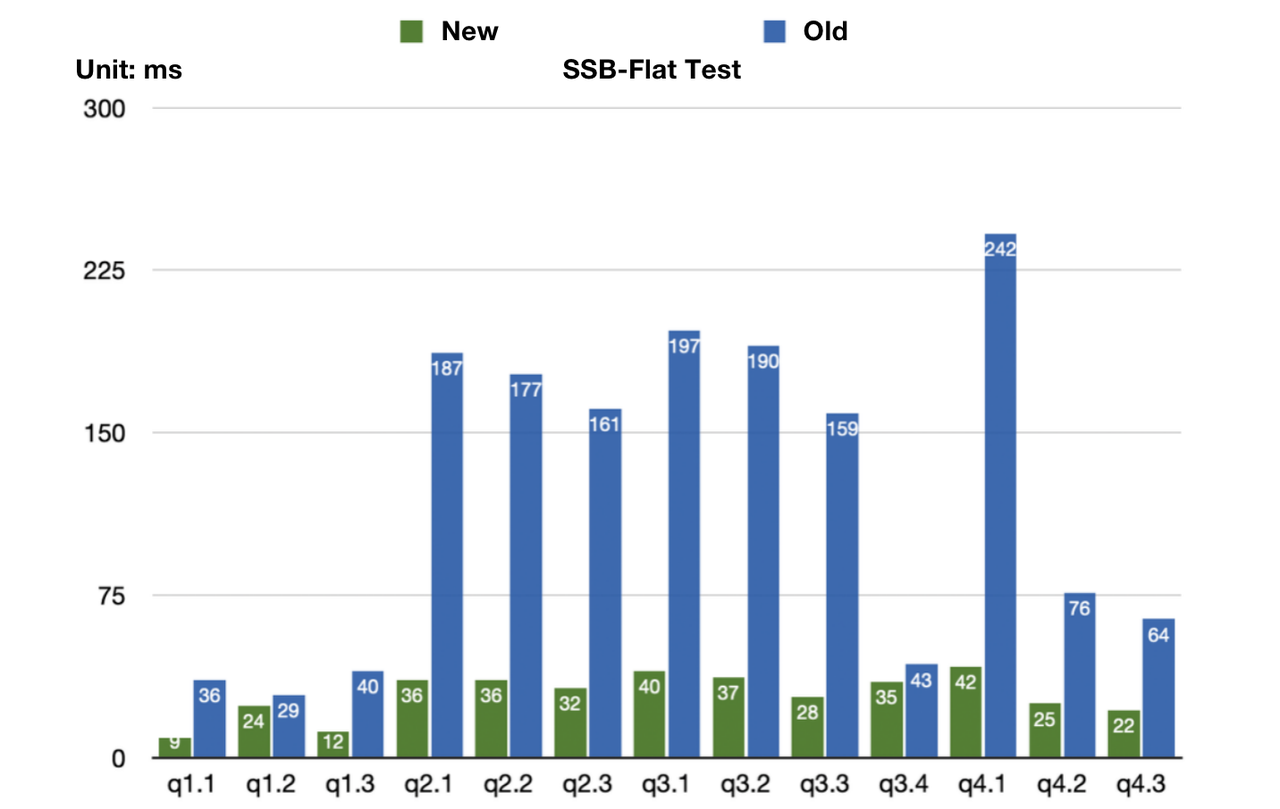
- Scenarios: It is suitable for users with requirements of primary key uniqueness and frequent needs of real-time Upsert updates.
- Usage: As a new feature, the Merge-on-Write implementation is disabled by default. You may enable it by adding the following Property to the CREATE TABLE statement:
“enable_unique_key_merge_on_write” = “true”
Due to the difference between versions, existing Unique Key tables do not support Merge-on-Write. Adding Property to the ALTER TABLE statement will not do the trick. You may only enable this implementation for newly created tables. You can use insert into new_table select * from old_table to convert an old table to a new one.
Multi Catalog
The Multi Catalog feature is to make it easier for users to interface with external data catalogs, and thus enhance Apache Doris' capabilities in Data Lake analysis and federated data query.
The previous versions only allows interfacing with external data sources at the Database or Table level. Hence, if the external data catalogs are of very different schema, or if they contain too many Databases or Tables, users will have to do manual mapping one by one, which is maintenance-intensive.
With the Multi Catalog feature in 1.2.0, you can connect to external data sources via the CREATE CATALOG command, and Doris will automatically map the external libraries and tables. After that, you can access the external data as easily as accessing internal data.
Currently, Multi Catalog supports the following data sources:
- Hive Metastore: You can access data tables including Hive, Iceberg, Hudi, and also dock to data sources compatible with Hive Metastore, such as Aliyun's DataLake Formation. It also supports data access on HDFS and object stores.
- Elasticsearch: You can access ES data sources.
- JDBC: You can access MySQL data sources via JDBC.
Note: The corresponding privilege levels will be changed automatically. See the Notes for Version Upgrade section for details.
Documentation:
https://doris.apache.org/docs/dev/ecosystem/external-table/multi-catalog
Light Schema Change
Schema Change used to be a burdenous job in Apache Doris. It involved modification of data files that largely reduced efficiency under large cluster size and large data volume in tables. Plus, any changes in the upstream schema would require a suspension of data synchronization for manual Schema Change operation. This could increase development and maintenance costs and induce backlog of consumption data.
In the new version, it is no longer necessary to change the data file synchronously when adding and subtracting columns to the data table. You only need to update the metadata in FE**. This enables millisecond-level Schema Change operation.** Users can use Flink CDC to realize DML and DDL synchronization from upstream database to Doris.
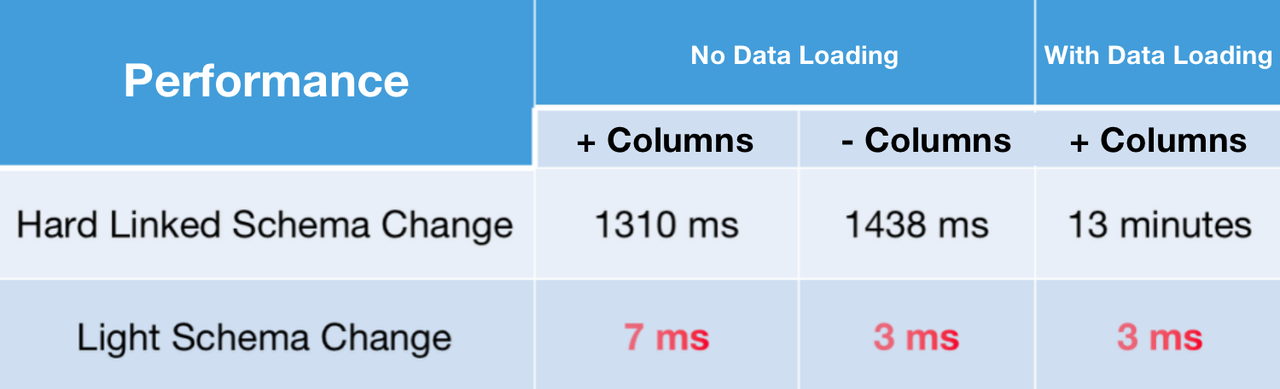
As a new feature, Light Schema Change is disabled by default. You may enable it by adding the following Property to the CREATE TABLE statement:
"light_schema_change"="true"
Documentation:
JDBC Facade
In older versions of Apache Doris, users used ODBC external tables to access data sources such as MySQL, Oracle, SQL Server, PostgreSQL, but since different ODBC driver versions may cause system instability, we decided to replace ODBC external tables with JDBC external tables in 1.2.0, as JDBC interfaces are more unified and support diverse databases. External data sources that support JDBC protocol can be connected to Apache Doris 1.2.0. Currently, we support the following sources and we are making continuous efforts to expand the list:
- MySQL
- PostgreSQL
- Oracle
- SQLServer
- ClickHouse
The ODBC feature will be removed in a later version. Please try to switch to the JDBC.
Documentation:
https://doris.apache.org/docs/dev/ecosystem/external-table/jdbc-of-doris/
Java UDF
Apache Doris 1.2.0 supports writing UDF/UDAF in Java in addition to C++, so users can use custom functions in the Java ecosystem. Meanwhile, through technologies such as off-heap memory and Zero Copy, the efficiency of cross-language data access has been greatly improved in 1.2.0.
Documentation:
https://doris.apache.org/docs/dev/ecosystem/udf/java-user-defined-function
Example: https://github.com/apache/doris/tree/master/samples/doris-demo
Remote UDF
The new version supports accessing remote UDF services through RPC, thus completely eliminating language restrictions for users to write UDFs. Users can use any programming language to implement custom functions and complete complex data analysis work.
Documentation:
https://doris.apache.org/docs/ecosystem/udf/remote-user-defined-function
Example: https://github.com/apache/doris/tree/master/samples/doris-demo
More Data Type Support
- Array type
The new version supports the Array type and nested Array types since the Array type is more applicable in scenarios such as user portraits and tags. We have also implemented a large number of array-related functions to better support the application of the Array type in actual usage.
Documentation:
https://doris.apache.org/docs/dev/sql-manual/sql-reference/Data-Types/ARRAY
Related functions:
https://doris.apache.org/docs/dev/sql-manual/sql-functions/array-functions/array_max
- JSONB type
The new version supports the JSONB type, which provides a more compact encoding format and data access in the encoding format. Compared with JSON data stored in strings, the use of the JSONB type can increase performance by several times.
Documentation: https://doris.apache.org/docs/dev/sql-manual/sql-reference/Data-Types/JSONB
Related functions: https://doris.apache.org/docs/dev/sql-manual/sql-functions/json-functions/jsonb_parse
Date V2/DatatimeV2
The new version supports Date V2 and DatatimeV2 data types, which are more efficient and support micro-second-level time accuracy.
Documentation:
- https://doris.apache.org/docs/dev/sql-manual/sql-reference/Data-Types/DATETIMEV2/
- https://doris.apache.org/docs/dev/sql-manual/sql-reference/Data-Types/DATEV2
Sphere of influence:
- Users need to specify DateV2 and DatetimeV2 when creating tables. The Date and Datetime of the existing tables will not be changed.
- If calculations are conducted between data of the new and old types (for example, equi-join), the old data types will be cast into the corresponding new types.
- See examples in the related documentation
New Memory Management Framework
In Apache Doris 1.2.0, we added a new Memory Tracker to record Doris BE process memory usage, including memory and cache space usage in queries, data loading, Compaction, and Schema Change. The Memory Tracker enables more fine-grained memory monitoring and control, which greatly reduces OOM problems caused by memory overruns and further improves system stability.
Documentation:
https://doris.apache.org/docs/dev/admin-manual/maint-monitor/memory-management/memory-tracker
Table Valued Function
Apache Doris 1.2.0 implements a set of Table Valued Function (TVF). TVF can be regarded as an ordinary table, which can appear in all places where "table" can appear in SQL.
For example, we can use S3 TVF to implement data import on object storage:
insert into tbl select * from s3("s3://bucket/file.*", "ak" = "xx", "sk" = "xxx") where c1 > 2;
Or directly query data files on HDFS:
insert into tbl select * from hdfs("hdfs://bucket/file.*") where c1 > 2;
TVF can help users make full use of the rich expressiveness of SQL and flexibly process various data.
Documentation:
https://doris.apache.org/docs/dev/sql-manual/sql-functions/table-functions/s3
https://doris.apache.org/docs/dev/sql-manual/sql-functions/table-functions/hdfs
More
1. A More Convenient Way to Create Partitions
Apache Doris 1.2.0 supports creating multiple partitions within a certain time range via the FROM TOcommand.
Documentation:
Example:
-- Create partitions based on DATE, supports the mixed use of batch create and single create
PARTITION BY RANGE(event_day)(
FROM ("2000-11-14") TO ("2021-11-14") INTERVAL 1 YEAR,
FROM ("2021-11-14") TO ("2022-11-14") INTERVAL 1 MONTH,
FROM ("2022-11-14") TO ("2023-01-03") INTERVAL 1 WEEK,
FROM ("2023-01-03") TO ("2023-01-14") INTERVAL 1 DAY,
PARTITION p_20230114 VALUES [('2023-01-14'), ('2023-01-15'))
)
-- Create partitions based on DATETIME
PARTITION BY RANGE(event_time)(
FROM ("2023-01-03 12") TO ("2023-01-14 22") INTERVAL 1 HOUR
)
2. Column Renaming
Apache Doris 1.2.0 supports column renaming for tables with Light Schema Change enabled.
Documentation:
3. More Fine-Grained Privilege Management
Support row-level privileges
Row-level privileges can be created with the
CREATE ROW POLICYcommand.Documentation: https://doris.apache.org/docs/dev/sql-manual/sql-reference/Data-Definition-Statements/Create/CREATE-POLICY
Support specifying password strength, expiration time, etc.
Support for locking accounts after multiple failed logins.
Documentation: https://doris.apache.org/docs/dev/sql-manual/sql-reference/Account-Management-Statements/ALTER-USER
4. More Import-Related Features
CSV import supports csv files with header.
Search for
csv_with_namesin the documentation: https://doris.apache.org/docs/dev/sql-manual/sql-reference/Data-Manipulation-Statements/Load/STREAM-LOAD/Stream Load adds
hidden_columns, which can explicitly specify the delete flag column and sequence column.Search for
hidden_columnsin the documentation: https://doris.apache.org/docs/dev/sql-manual/sql-reference/Data-Manipulation-Statements/Load/STREAM-LOADSpark Load supports Parquet and ORC file import.
Support for cleaning completed imported Labels
Documentation: https://doris.apache.org/docs/dev/sql-manual/sql-reference/Data-Manipulation-Statements/Load/CLEAN-LABEL
Support batch cancellation of import jobs by status
Documentation: https://doris.apache.org/docs/dev/sql-manual/sql-reference/Data-Manipulation-Statements/Load/CANCEL-LOAD
Added support for Alibaba Cloud oss, Tencent Cloud cos/chdfs and Huawei Cloud obs in broker load.
Documentation: https://doris.apache.org/docs/dev/advanced/broker
Support access to hdfs through hive-site.xml file configuration.
Documentation: https://doris.apache.org/docs/dev/admin-manual/config/config-dir
5. Support Viewing the Catalog Recycle Bin
Apache Doris 1.2.0 supports viewing the catalog recycle bin through the show catalog recycle bin function.
Documentation:
https://doris.apache.org/docs/dev/sql-manual/sql-reference/Show-Statements/SHOW-CATALOG-RECYCLE-BIN
6. Support SELECT * EXCEPT syntax
Documentation:
https://doris.apache.org/docs/dev/data-table/basic-usage
7. Outfile Supports ORC Format Export and Multi-Byte Delimiters
Documentation:
https://doris.apache.org/docs/dev/sql-manual/sql-reference/Data-Manipulation-Statements/OUTFILE
8. Support to Modify the Number of Query Profiles That Can Be Saved Through Configuration
Search FE configuration item in the documentation: max_query_profile_num
9. DELETE Statement supports IN Predicate Conditions and Partition Pruning
Documentation:
10. Default Value of the Time Column Supporting Current_timestamp
Search "CURRENT_TIMESTAMP" in the documentation: https://doris.apache.org/docs/dev/sql-manual/sql-reference/Data-Definition-Statements/Create/CREATE-TABLE
11. Added Two System Tables: Backends, Rowsets
Documentation:
https://doris.apache.org/docs/dev/admin-manual/system-table/backends
https://doris.apache.org/docs/dev/admin-manual/system-table/rowsets
12. Backup and Restore
The Restore job supports the
reserve_replicaparameter, so that the number of replicas of the restored table is the same as that of the backup.The Restore job supports
reserve_dynamic_partition_enableparameter, so that the restored table keeps the dynamic partition enabled.Documentation:
Support backup and restore operations through the built-in libhdfs, no longer rely on broker.
Documentation:
13. Support Data Balance Between Multiple Disks on the Same Machine
Documentation:
14. Routine Load supports subscribing to Kerberos-authenticated Kafka services
Search for kerberos in the documentation: https://doris.apache.org/docs/dev/data-operate/import/import-way/routine-load-manual
15. New Built-in Functions
Added the following built-in functions:
cbrtsequence_match/sequence_countmask/mask_first_n/mask_last_neltany/any_valuegroup_bitmap_xorntilenvluuidinitcapregexp_replace_one/regexp_extract_allmulti_search_all_positions/multi_match_anydomain/domain_without_www/protocolrunning_differencebitmap_hash64murmur_hash3_64to_mondaynot_null_or_emptywindow_funnelgroup_bit_and/group_bit_or/group_bit_xorouter combine- and all array functions
Upgrade Notice
Known Issues
- Use JDK11 will cause BE crash, please use JDK8 instead.
Behavior Changed
Permission level changes
Because the catalog level is introduced, the corresponding user permission level will also be changed automatically. The rules are as follows:
- GlobalPrivs and ResourcePrivs remain unchanged
- Added CatalogPrivs level.
- The original DatabasePrivs level is added with the internal prefix (indicating the db in the internal catalog)
- Add the internal prefix to the original TablePrivs level (representing tbl in the internal catalog)
In GroupBy and Having clauses, match on column names in preference to aliases. (#14408)
Creating columns starting with
mv_is no longer supported.mv_is a reserved keyword in materialized views (#14361)Removed the default limit of 65535 rows added by the order by statement, and added the session variable
default_order_by_limitto configure this limit. (#12478)In the table generated by "Create Table As Select", all string columns use the string type uniformly, and no longer distinguish varchar/char/string (#14382)
In the audit log, remove the word
default_clusterbefore the db and user names. (#13499) (#11408)Add sql digest field in audit log (#8919)
The union clause always changes the order by logic. In the new version, the order by clause will be executed after the union is executed, unless explicitly associated by parentheses. (#9745)
During the decommission operation, the tablet in the recycle bin will be ignored to ensure that the decomission can be completed. (#14028)
The returned result of Decimal will be displayed according to the precision declared in the original column, or according to the precision specified in the cast function. (#13437)
Changed column name length limit from 64 to 256 (#14671)
Changes to FE configuration items
- The
enable_vectorized_loadparameter is enabled by default. (#11833) - Increased
create_table_timeoutvalue. The default timeout for table creation operations will be increased. (#13520) - Modify
stream_load_default_timeout_seconddefault value to 3 days. - Modify the default value of
alter_table_timeout_secondto one month. - Increase the parameter
max_replica_count_when_schema_changeto limit the number of replicas involved in the alter job, the default is 100000. (#12850) - Add
disable_iceberg_hudi_table. The iceberg and hudi appearances are disabled by default, and the multi catalog function is recommended. (#13932)
- The
Changes to BE configuration items
- Removed
disable_stream_load_2pcparameter. 2PC's stream load can be used directly. (#13520) - Modify
tablet_rowset_stale_sweep_time_secfrom 1800 seconds to 300 seconds. - Redesigned configuration item name about compaction (#13495)
- Revisited parameter about memory optimization (#13781)
- Removed
Session variable changes
Modify the variable
enable_insert_strictto true by default. This will cause some insert operations that could be executed before, but inserted illegal values, to no longer be executed. (11866)Modified variable
enable_local_exchangeto default to true (#13292)Default data transmission via lz4 compression, controlled by variable
fragment_transmission_compression_codec(#11955)Add
skip_storage_engine_mergevariable for debugging unique or agg model data (#11952)Documentation: https://doris.apache.org/docs/dev/advanced/variables
The BE startup script will check whether the value is greater than 200W through
/proc/sys/vm/max_map_count. Otherwise, the startup fails. (#11052)Removed mini load interface (#10520)
FE Metadata Version
FE Meta Version changed from 107 to 114, and cannot be rolled back after upgrading.
During Upgrade
Upgrade preparation
- Need to replace: lib, bin directory (start/stop scripts have been modified)
- BE also needs to configure JAVA_HOME, and already supports JDBC Table and Java UDF.
- The default JVM Xmx parameter in fe.conf is changed to 8GB.
Possible errors during the upgrade process
- The repeat function cannot be used and an error is reported:
vectorized repeat function cannot be executed, you can turn off the vectorized execution engine before upgrading. (#13868) - schema change fails with error:
desc_tbl is not set. Maybe the FE version is not equal to the BE(#13822) - Vectorized hash join cannot be used and an error will be reported.
vectorized hash join cannot be executed. You can turn off the vectorized execution engine before upgrading. (#13753)
The above errors will return to normal after a full upgrade.
- The repeat function cannot be used and an error is reported:
Performance Impact
- By default, JeMalloc is used as the memory allocator of the new version BE, replacing TcMalloc (#13367)
- The batch size in the tablet sink is modified to be at least 8K. (#13912)
- Disable chunk allocator by default (#13285)
API change
BE's http api error return information changed from
{"status": "Fail", "msg": "xxx"}to more specific{"status": "Not found", "msg": "Tablet not found. tablet_id=1202"}(#9771)In
SHOW CREATE TABLE, the content of comment is changed from double quotes to single quotes (#10327)Support ordinary users to obtain query profile through http command. (#14016) Documentation: https://doris.apache.org/docs/dev/admin-manual/http-actions/fe/manager/query-profile-action
Optimized the way to specify the sequence column, you can directly specify the column name. (#13872) Documentation: https://doris.apache.org/docs/dev/data-operate/update-delete/sequence-column-manual
Increase the space usage of remote storage in the results returned by
show backendsandshow tablets(#11450)Removed Num-Based Compaction related code (#13409)
Refactored BE's error code mechanism, some returned error messages will change (#8855) other
Support Docker official image.
Support compiling Doris on MacOS(x86/M1) and ubuntu-22.04 Documentation: https://doris.apache.org/docs/dev/install/source-install/compilation-mac/
Support for image file verification.
Documentation: https://doris.apache.org/docs/dev/admin-manual/maint-monitor/metadata-operation/
Script related
- The stop scripts of FE and BE support exiting FE and BE via the
--graceparameter (use kill -15 signal instead of kill -9) - FE start script supports checking the current FE version via --version (#11563)
- The stop scripts of FE and BE support exiting FE and BE via the
Support to get the data and related table creation statement of a tablet through the
ADMIN COPY TABLETcommand, for local problem debugging (#12176)Documentation: https://doris.apache.org/docs/dev/sql-manual/sql-reference/Database-Administration-Statements/ADMIN-COPY-TABLET
Support to obtain a table creation statement related to a SQL statement through the http api for local problem reproduction (#11979)
Documentation: https://doris.apache.org/docs/dev/admin-manual/http-actions/fe/query-schema-action
Support to close the compaction function of this table when creating a table, for testing (#11743)
Search for "disble_auto_compaction" in the documentation: https://doris.apache.org/docs/dev/sql-manual/sql-reference/Data-Definition-Statements/Create/CREATE-TABLE
